作成した棋譜を使って、MCTSの手を学習するモデルを作りたい。
UTTTの盤面は、$9\times9$の81マスに2種類のマーク(oとx)が散りばめられた形になっていて、作成した棋譜では各マスに以下のように番号を振ってある。
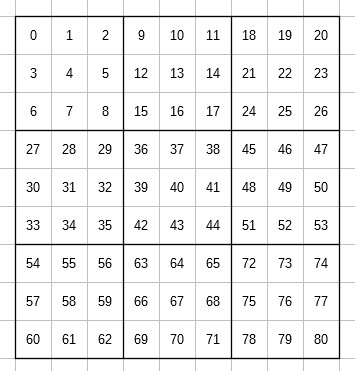
これはゲームエンジン作成の都合でこのようになっていて、エンジン内部でも同様の方法で盤面を処理している。
たとえば棋譜上で盤面が
"board": [2, 1, 0, 2, 0, 0, 2, 1, 0, 0, 0, 2, 0, 0, 0, 0, 2, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 1, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 2, 2, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
と表されている場合、それは以下のような盤面を表している(青が自分)
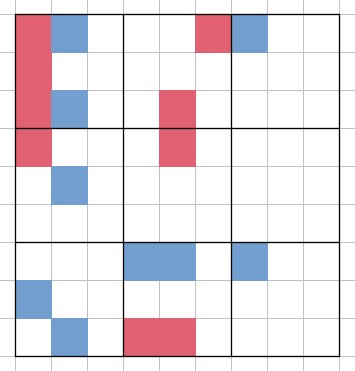
実際のゲームでは、このような形の盤面データに加えて自分が次にマークすることができる場所のリストが与えられる。それが棋譜上で
"legal": [9, 10, 12, 13, 14, 15, 17]
と書かれているなら、それはこのターンに自分が以下の緑の場所にマークしてよいことを表している。

それに対して、エージェントは緑のマスの中から自分のマークしたいマスを1つ選んで、その番号を返す(たとえば12など)
あるエージェントが打った手を学習するとき、これは盤面を表す81ピクセルの4色画像に対して0から80までのラベルを判定する分類問題であると考えられる。
ここで、盤面を3倍の大きさにコピーし、1つ目に自分のマークを、2つ目に相手のマークを、3つめに合法手を表示することで、白黒の2値画像として盤面を扱うことができる。
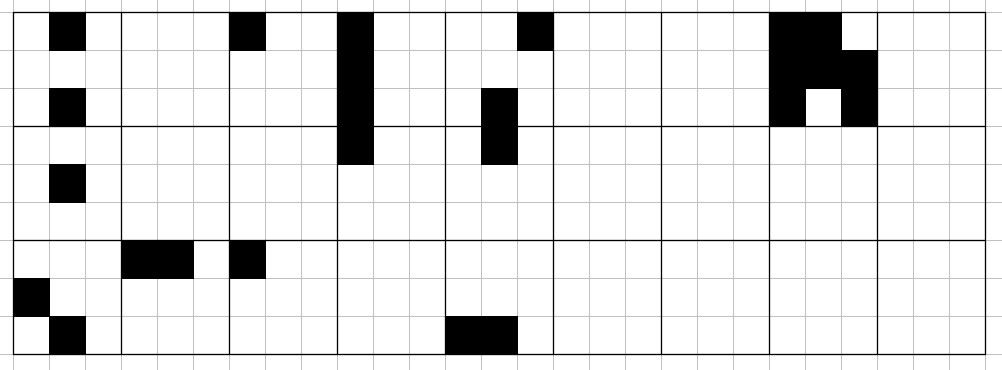
これで、UTTTを長さ243のbit列を80種類のラベルに分類する問題と読み替えることができた。これはMNISTと同じタイプの問題なので、同じ方法で学習できるだろう。MNISTとの違いは、画像のサイズ(MNISTは784ピクセル)、各ピクセルの値の種類(MNISTはグレースケールなので、0~255)、ラベルの数(MNISTは10種類)といったところだろうか。あとは、MCTSエージェントはランダム要素を含むため同じ盤面でも異なる場所にマークする可能性があり、棋譜にも同じ”画像”に対して異なるラベルがついているものがいくつも存在すると考えられる。ほかには、MNISTでは似た画像は同じラベルになりやすいのに対して、UTTTではマークの場所が一つずれるだけで次に指すべき場所は全く変わってしまう点が大きく違う。
大半は大した問題にはならないだろうと思っているが、最後のものだけはもしかすると学習の精度に大きな影響を与えるかもしれない。実際にやってみればはっきりするだろう。
戻る