$$
\def\bra#1{\mathinner{\left\langle{#1}\right|}}
\def\ket#1{\mathinner{\left|{#1}\right\rangle}}
\def\braket#1#2{\mathinner{\left\langle{#1}\middle|#2\right\rangle}}
$$
◇◇UTTT009:強化学習編①:とりあえず動かしてみる◇◇
とりあえず強化学習を実装してみた。
前回まとめた内容によると、UTTTの強化学習を行う際、パラメータの更新は
$$\rho \leftarrow \rho + \frac\alpha N\sum_n\frac{z_{T_n}^i}{T_n}\sum_t\frac{\partial}{\partial\rho} \log{\pi_\rho(a_t^n|s_t^n)}$$
のようにするとよく、学習率は
$$\alpha' = \frac{\alpha z^i_{T_n}}{T_n}$$
とすればいいという結論になった。ここで、学習率には終局までに打った手の数$T_n$が含まれているので、同じ手数で終わった試合のみを集めることで実装が簡単になる。
今回は、以下のようなサイクルで実際に学習を回してみた
-
学習する側のエージェントを先手、相手役のエージェントを後手として、UTTTを1024ゲームプレイする。
-
生成された棋譜から学習側が指した局面の情報を取り出し、各局面を試合終了までのターン数と勝敗で分類して記録する。
-
あるターン数の局面の集合が2048以上のサイズになったら、ランダムに1024局面を取り出して1ミニバッチとして学習する。
モデルが小さいことからバッチサイズ1024で問題なく推論・学習ができることを教師あり学習で確認していたので、これを1単位とした。こうすることで対戦を1024並列で行うことができた(もっとも、1024並列なのは推論部分だけでCPUの仕事はかなり直列に近い)、手番を固定していることには特に意味はなく、単に実装が楽だからである。自宅のGPU(GeForce RTX3080)では、1サイクルが大体1分程度であった。
また、負け試合の学習の際に学習率を負の値にする必要があったが、PyTorchでは学習率を負にできない仕様になっていた。しかし、引数を見て例外で弾いているだけだったので、ライブラリを書き換えることで問題なく動作した(多分)。初期ポリシーは学習側、相手役ともに教師あり学習で生成したSLポリシーを使用し、相手役のポリシーの交換は、今回は行わなかった。
以上のような条件で、$\alpha = 0.0001$として200サイクル程度学習させた結果、勝率の推移は以下のようになった。
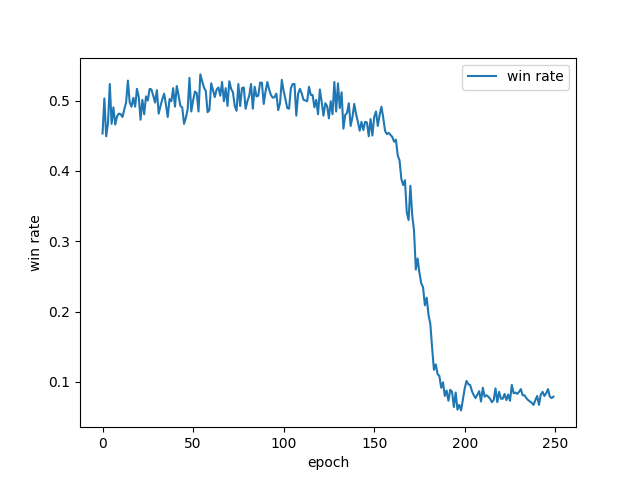 50サイクルから100サイクルあたりで勝率が平均的に50%よりほんのわずかに高くなり、その後200サイクルにかけて急激に降下し、最後は10%未満まで落ちている。ちなみに、今回は引き分けを負けに分類しているので最初の勝率は5割より少し低くなっている(初期ポリシー自体は学習側のほうが若干強い)。この後もさらに数百サイクルほど観察していたが、勝率が再び上昇に転じることはなかった。
学習率が少し高かったかもしれないと思い、$\alpha = 0.00001$としたところ、以下のような推移となった。
50サイクルから100サイクルあたりで勝率が平均的に50%よりほんのわずかに高くなり、その後200サイクルにかけて急激に降下し、最後は10%未満まで落ちている。ちなみに、今回は引き分けを負けに分類しているので最初の勝率は5割より少し低くなっている(初期ポリシー自体は学習側のほうが若干強い)。この後もさらに数百サイクルほど観察していたが、勝率が再び上昇に転じることはなかった。
学習率が少し高かったかもしれないと思い、$\alpha = 0.00001$としたところ、以下のような推移となった。
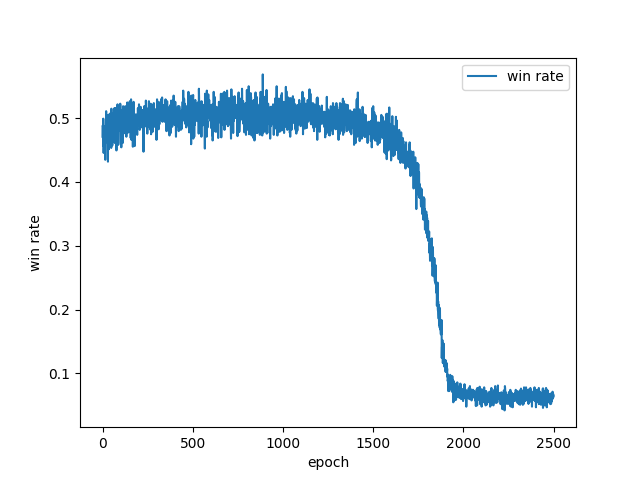 見てわかるとおり、時間スケールが10倍になっただけで全く同じ経過をたどっている。ちなみに教師あり学習は学習率$0.01$で行っていたので、ターン数で割ることを考えると$\frac1{10000}$以下の学習率となっている。
勝率の遷移に再現性があるので、単純に学習がうまくいっておらず、最初ある程度強かったポリシーが徐々に崩れていくさまを観察しているだけの可能性が充分あると思う(ちなみに勝率が落ち切ったあとの強さはランダムとほとんど同じくらいになっている。)
学習がうまくいっていない理由はまだ分かっていないが、ネットワークの構成よりは強化学習の方法に問題がありそうだと思っている。AlphaGOではもっとたくさんの工夫をしているようなので、それらを参考にして学習方法を改良してみたい。
見てわかるとおり、時間スケールが10倍になっただけで全く同じ経過をたどっている。ちなみに教師あり学習は学習率$0.01$で行っていたので、ターン数で割ることを考えると$\frac1{10000}$以下の学習率となっている。
勝率の遷移に再現性があるので、単純に学習がうまくいっておらず、最初ある程度強かったポリシーが徐々に崩れていくさまを観察しているだけの可能性が充分あると思う(ちなみに勝率が落ち切ったあとの強さはランダムとほとんど同じくらいになっている。)
学習がうまくいっていない理由はまだ分かっていないが、ネットワークの構成よりは強化学習の方法に問題がありそうだと思っている。AlphaGOではもっとたくさんの工夫をしているようなので、それらを参考にして学習方法を改良してみたい。
〇 追記
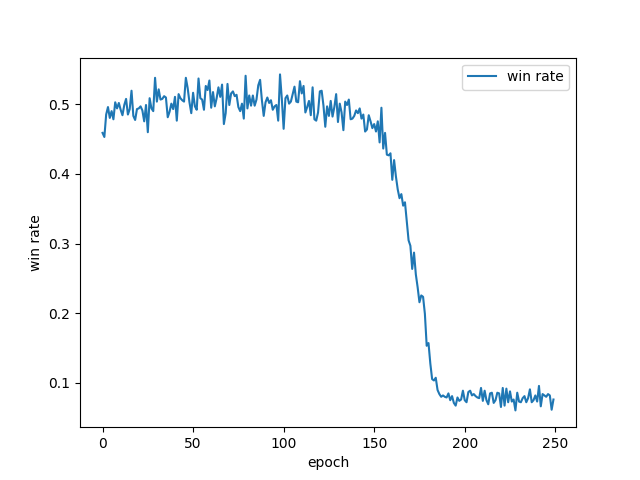
改良しようと思い実装を見直していたところ、サイクル中で取り出した1024局面を捨てて、残った局面たちをバッチとして学習していることに気がついた。このミスを修正したら少しよくなるかと思ったが、無事(?)結果は変わらなかった。
戻る