前回作った強化学習のシステムでは、パラメータの更新をする際 $$\rho \leftarrow \rho + \frac\alpha N\sum_n\frac{1}{T_n}\sum_t\frac{\partial}{\partial\rho} \log{\pi_\rho(a_t^n|s_t^n)}z_{T_n}^i$$ のようにしており、同じゲーム中に指した手にはすべて同じ報酬を与えていた。しかし、このような方法を用いると、形勢の有利不利を考慮していないため不都合がある。
たとえば、自分がとても有利な状況では1手くらいは適当に指してもそのまま勝つ場合が多いと考えられるが、上述の方法ではそのような場合に適当に指した(全然良くない)手にもほかの手と同様の報酬を与えてしまうことになる。
AlphaGOでは、これを防ぐために盤面の評価値を用いているらしい。つまり、盤面$s_t^i$に対してその評価値を$v(s_t^i)$として $$\rho \leftarrow \rho + \frac\alpha N\sum_n\frac{1}{T_n}\sum_t\frac{\partial}{\partial\rho} \log{\pi_\rho(a_t^n|s_t^n)}\left(z_{T_n}^i - v(s_t^i) \right)$$ のように更新している。こうすることで、自分が勝ったとき、有利な盤面で指した手には小さな報酬を、不利な盤面で指した手には大きな報酬を与えることができる。負けた場合には、有利な盤面で指した手には大きなペナルティを、不利な盤面で指した手には小さなペナルティを与えることになる。
これを実装するためには各盤面に対してその評価値を知る必要があるので、バリューネットワークを用いて評価値を学習することを考える。
バリューネットワークは基本的な構成はポリシーネットワークと同様だが、出力が盤面の評価値となっているので出力ノードは1つだけである点が異なる。バリューネットワークの学習の際には、損失関数として二乗誤差 $$L_\theta = \sum_{k = 1}^M \left( z^k - y_\theta(s^k) \right)^2$$ を用いる。ここで、$z^k, y^k$はそれぞれ$k$番目の学習データの正解と出力である。 パラメータ$\theta$の更新は \begin{align*} \theta &\leftarrow \theta -\frac{\partial L_\theta}{\partial \theta} \\ & = \theta +\sum_{k = 1}^M 2\left( z^k - y_\theta(s^k) \right) \frac{\partial y_\theta(s^k)}{\partial \theta} \end{align*} のように行う。PyTorchではMSELoss関数を用いればよい。強化学習では、バリューネットワークの出力にtanh関数をかけて[-1, 1]の範囲に射影したものを盤面の評価値として扱う。
ということで、とりあえずバリューネットワークを学習させてみることにした。
バリューネットワークを作るためには盤面のデータと勝敗のデータがたくさん必要だが、UTTTではプロ同士の棋譜などは存在しない(たぶん)ので、AlphaGOにならって教師データを作ることにした。その手順は以下である。
このようにして、1試合ごとに局面と勝敗のペアが1つずつできるので、それを使って盤面の評価値を学習する。本来は手順3ではRL(強化学習)ポリシーを使うとのことだが、今回はまだ強化学習がうまくいってないのでSLポリシーをそのまま使ってみた。
こうして教師データを400万局面ほど作り、ポリシーネットワークの出力ノードを1つに変えたネットワークで評価値を学習させたところ、学習が全く進まなかった。

例によってメモリに乗りきらないので、ファイルを80個強に分けて、10エポックごとにランダムな10ファイルを読み込むという方法で学習させた。青がtrain loss、橙がtest lossである。
ここで、試合途中の1局面とその勝敗だけではうまく特徴をとらえられていない可能性が高いので、教師あり学習で作ったポリシーネットワークのパラメータを特徴抽出器として使用し、下3層の重みだけを再学習(転移学習)させたところ、lossが下がっていくのを確認できた。
この状態から全パラメータの固定を解除(ファインチューニング)すると、さらにlossが下がった。
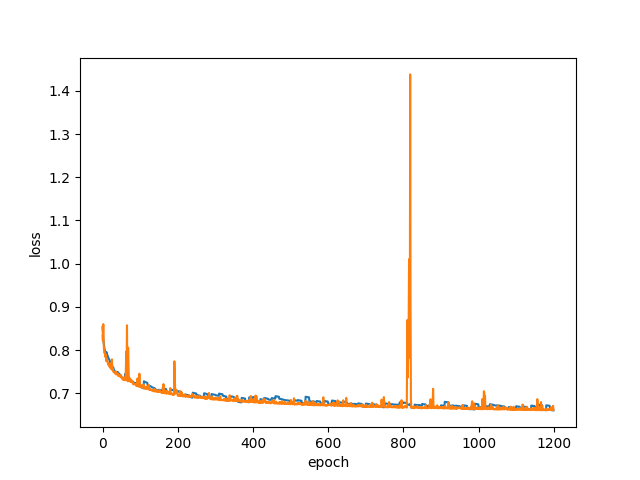
途中で一度lossが跳ねあがったせいでグラフが非常に見づらくなってしまったが、0.7を切っている。
作ったバリューネットワークを使って盤面の評価値を表示しながらいくつか試合をさせてみたところ、上手く評価できている(決着の盤面が評価値プラス0.6~プラス0.7程度、その前の相手の盤面がマイナス0.5~マイナス0.6程度)場合が多かったが、決着の盤面が評価0に近かったり、マイナス0.6程度になっているときもあった。うまく評価できていない場合の決着盤面をよく見ると、大抵は自分と相手が両方リーチになっている盤面(自分の番だったら自分の勝ちで、相手の番だったら相手が勝ちの盤面)になっていた。つまり、自分がリーチであるというプラスの要素と相手がリーチであるというマイナスの要素がせめぎあった結果、マイナスが大きく評価されている場合があると考えられる。
与えられる盤面は必ず自分のターンなので、本来は自分がリーチでさえあれば相手がリーチであろうと関係ないはずだが、そこがうまく表現できていない気がした。なにかいい方法がないだろうか。
戻る